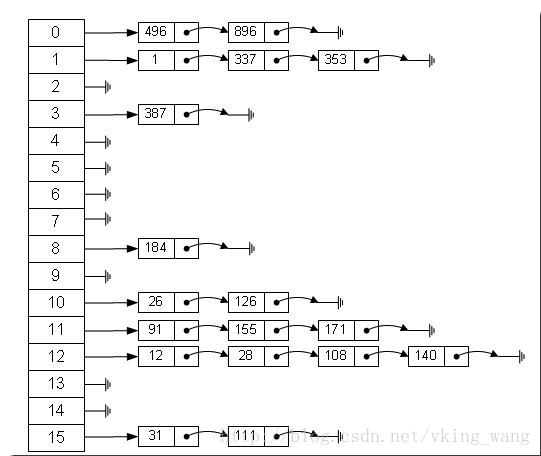
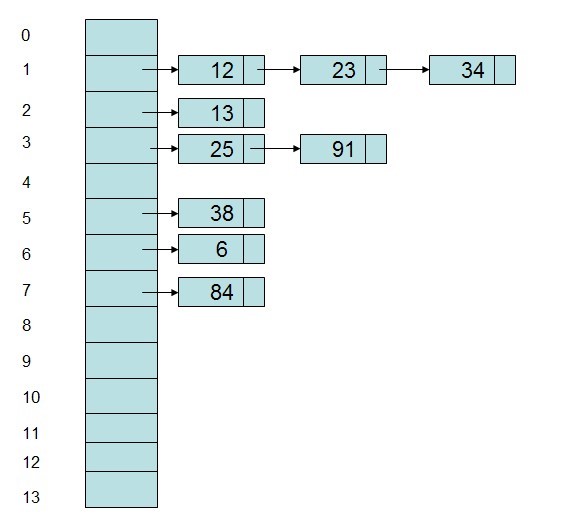
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
#include <string>
template <typename key_type, typename value_type>
class HashNode {
public:
key_type key_;
value_type value_;
HashNode *next_;
HashNode(key_type key, value_type value) {
key_ = key;
value_ = value;
next_ = nullptr;
}
~HashNode() {}
HashNode& operator=(const HashNode& node) {
key_ = node.key;
value_ = node.value;
next_ = node.next;
return *this;
}
};
template <typename key_type, typename value_type, typename HashFunc>
class HashTable {
public:
HashTable(int size);
~HashTable();
bool insert(const key_type& key, const value_type& value);
bool del(const key_type& key);
value_type& find(const key_type& key);
value_type& operator[](const key_type& key);
private:
HashFunc hash;
HashNode<key_type, value_type> **table;
unsigned int size_;
value_type value_null;
};
template <typename key_type, typename value_type, typename HashFunc>
HashTable<key_type, value_type, HashFunc>::HashTable(int size) : size_(size) {
hash = HashFunc();
table = new HashNode<key_type, value_type> *[size_];
for (int i = 0; i < size_; i++) table[i] = nullptr;
value_null = NULL;
}
template<typename key_type, typename value_type, typename HashFunc>
HashTable<key_type, value_type, HashFunc>::~HashTable() {
for (int i = 0; i < size_; i++) {
HashNode<key_type, value_type> *cur_node = table[i];
while (cur_node) {
HashNode<key_type, value_type> *temp = cur_node;
cur_node = cur_node->next_;
delete temp;
temp = nullptr;
}
}
delete table;
table = nullptr;
}
template<typename key_type, typename value_type, typename HashFunc>
bool HashTable<key_type, value_type, HashFunc>::insert(const key_type &key, const value_type &value) {
value_type &temp = find(key);
if (temp != value_null) {
temp = value;
}
else {
int index = hash(key) % size_;
HashNode<key_type, value_type> *node = new HashNode<key_type, value_type>(key, value);
node->next_ = table[index];
table[index] = node;
}
return true;
}
template<typename key_type, typename value_type, typename HashFunc>
bool HashTable<key_type, value_type, HashFunc>::del(const key_type& key) {
int index = hash(key) % size_;
HashNode<key_type, value_type> *node = table[index];
HashNode<key_type, value_type> *pre = nullptr;
while (node) {
if (node->key_ == key) {
if (!pre) table[index] = node->next_;
else pre->next_ = node->next_;
delete node;
node = nullptr;
return true;
}
pre = node;
node = node->next_;
}
return false;
}
template<typename key_type, typename value_type, typename HashFunc>
value_type& HashTable<key_type, value_type, HashFunc>::find(const key_type& key) {
int index = hash(key) % size_;
if (table[index]) {
HashNode<key_type, value_type> *node = table[index];
while (node) {
if (node->key_ == key) {
return node->value_;
}
node = node->next_;
}
}
return value_null;
}
template<typename key_type, typename value_type, typename HashFunc>
value_type& HashTable<key_type, value_type, HashFunc>::operator[](const key_type& key) {
value_type &value = find(key);
if (value == value_null) {
int index = hash(key) % size_;
HashNode<key_type, value_type> *node = new HashNode<key_type, value_type>(key, value);
node->next_ = table[index];
table[index] = node;
return node->value_;
}
return value;
}
class HashFunc {
public:
int operator()(const std::string &key) {
int hash = 0;
for (int i = 0; i < key.length(); ++i) {
hash = hash << 7 ^ key[i];
}
return (hash & 0x7FFFFFFF);
}
};
|