图的定义 图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
注意:
线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex) 。
线性表中可以没有数据元素,称为空表。树中可以没有结点,叫做空树。在图结构中,不允许没有顶点 。在定义中,若 V 是顶点的集合,则强调了顶点集合 V 有穷非空(关于点集是否为空有争议)。
线性表中,相邻的数据元素之间具有线性关系,树结构中,相邻两层的结点具有层次关系,而图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的 。
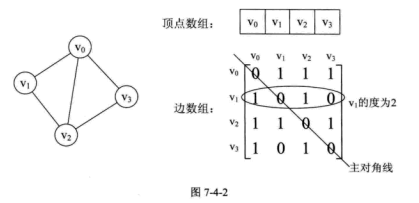
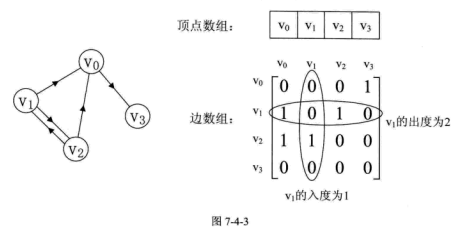
无向图 :图中任意两个顶点之间的边都是无向边(顶点之间的边没有方向,用无序偶对($v_i, v_j$)表示)。有向图 :图中任意两个顶点之间的边都是有向边(从顶点$v_i$ 到 $v_j$的边有方向,用有序偶对\<$v_i, v_j$>来表示,也称为弧,$v_i$为弧尾,$v_j$为弧头)。简单图 :图中不存在顶点到其自身的边,且一条边不重复出现的图。无向完全图 :无向图中任意两个顶点之间都存在边的图。有向完全图 :有向图中任意两个顶点之间都存在方向互为相反的两条弧的图。稀疏图 :有很少条边或者弧的图,反之称为稠密图。网(Network) :带权(weight,与图的边或者弧相关的数)的图
对于无向图,顶点v的度 是和该顶点相关联的边的数目,记为TD(v);v的入度 ,记为ID(v);以v为尾的弧的数目称为v的出度 ,记为OD(v);
路径的长度是路径上的边或弧的数目。回路或环(Cycle) 。序列中顶点不重复出现的路径称为简单路径 。除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环 。
在无向图 G 中,如果从顶点$v_i$到顶点$v_j$有路径,则称$v_i$和$v_j$是连通的。如果对于连通图 。连通分量 。它强调:
要是子图;
子图要是联通的;
连通子图含有极大顶点数;
具有极大顶点数的连通子图包含依附于这些顶点的所有边。
在有向图 G 中,如果对于每一对的$v_i, v_j∈V$、$v_i ≠ v_j$,从$v_i$和$v_j$和从$v_j$和$v_i$都存在路径,则称 G 是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。
一个连通图的生成树 是一个极小的连通子图,它含有图中全部的 n 个顶点,但只有足以构成一棵树的 n-1 条边。有向树 。有向图的生成森林 由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。
图的存储结构 邻接矩阵 图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
缺点:对于边数相对顶点较少的图,对存储空间有较大浪费。
1 2 3 4 5 6 7 8 9 #define MAX_VEX 100 template <typename VertexType, typename EdgeType>struct AMGraph { VertexType vexs[MAX_VEX]; EdgeType arc[MAX_VEX][MAX_VEX]; int num_vertexes, num_edges; };
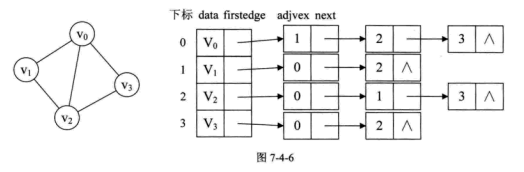
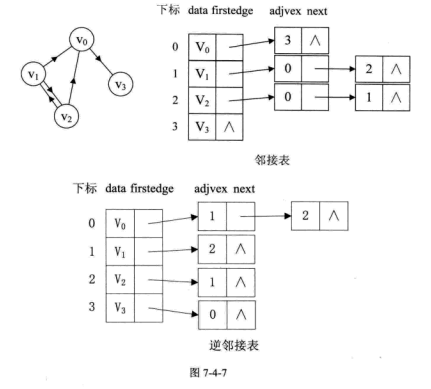
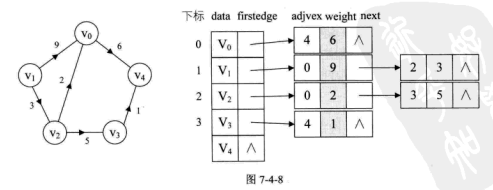
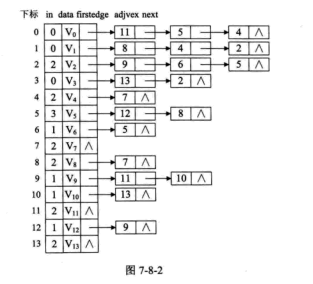
邻接表 对边或弧使用链式存储的方式来避免空间浪费的问题,这种数组与链表相结合的存储方法称为邻接表。
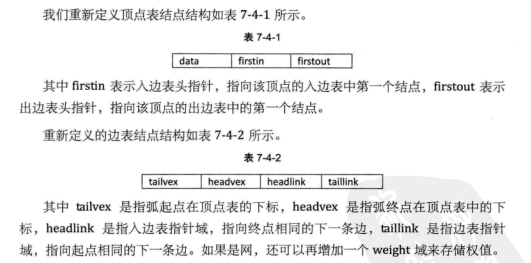
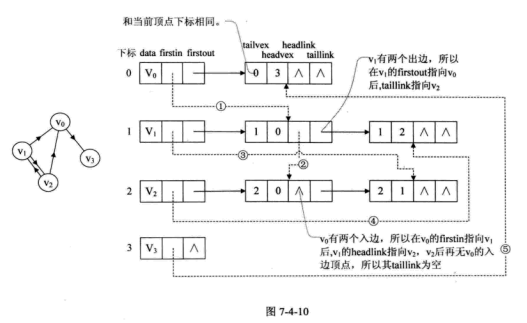
有向图的逆邻接表 :对每个顶点$v_i$都建立一个链接为$v_i$为弧头的表.
对于带权值的网图,可以在边表结点定义中再增加一个 weight 的数据域,存储权值信息即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 template <typename EdgeType>struct EdgeNode { int adjvex; EdgeType weight; EdgeNode *next; }; template <typename VertexType, typename EdgeType>struct VertexNode { VertexType data; EdgeNode<EdgeType> *firstedge; }; template <typename VertexType, typename EdgeType>struct ALGraph { VertexNode<VertexType, EdgeType> adj_list[MAX_VEX]; int num_vertexes, num_edges; };
十字链表 十字链表:把邻接表与逆邻接表结合起来的存储方法。
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起,这样既容易找到以$v_i$为尾的弧,也容易找到以$v_i$为头的弧,因而容易求得顶点的出度和入度。而且它除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图的应用中,十字链表是非常好的数据结构模型。
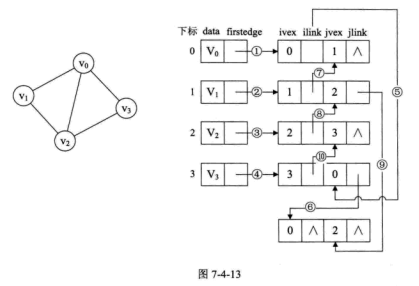
邻接多重表
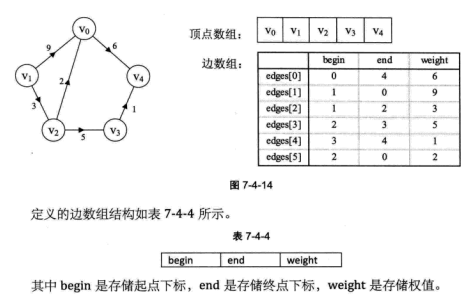
边集数组 边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组毎个数据元素由一条边的起点下标(begin)终点下标(end)和权(weight)组成。
边集数组关注的是边的集合,在边集数组中要查找一个顶点的度需要扫描整个边数组,效率并不高。因此它更适合对边依次进行处理的操作,而不适合对顶点相关的操作。
图的遍历 从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历 (Traversing Graph)。
深度优先遍历 深度优先遍历 (Depth_First_Search),也称为深度优先搜索,简称为 DFS 。它从图中某个顶点 v 出发,访问此顶点,然后从 v 的未被访问的邻接点出发深度优先遍历图,直至图中所有和 v 有路径相通的顶点都被访问到。 事实上,我们这里讲到的是连通图,对于非连通图,只需要对它的连通分量分别进行深度优先遍历,即在先前一个顶点进行一次深度优先遍历后,若图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 bool visited_[MAX_VEX];void DFS (AMGraph<VertexType, EdgeType> *&am_graph, int i) int j; visited_[i] = true ; cout << am_graph->vexs[i] << endl ; for (j = 0 ; j < am_graph->num_vertexes; j++) { if (am_graph->arc[i][j] == 1 && !visited_[j]) { DFS(am_graph, j); } } } void DFSTraverse (AMGraph<VertexType, EdgeType> *&am_graph) int i; for (i = 0 ; i < am_graph->num_vertexes; i ++) { visited_[i] = false ; } for (i = 0 ; i < am_graph->num_vertexes; i++) { if (!visited_[i]) { DFS(am_graph, i); } } } void DFS (ALGraph<VertexType, EdgeType> *&al_graph, int i) EdgeNode<EdgeType> *edge; visited_[i] = true ; cout << al_graph->vexs[i] << endl ; edge = al_graph->adj_list[i].firstedge; while (edge) { if (!visited[edge->adjvex]) { DFS(al_graph, edge->adjvex); } edge = edge->next; } } void DFSTraverse (ALGraph<VertexType, EdgeType> *&al_graph) int i; for (i = 0 ; i < al_graph->num_vertexes; i++) { visited_[i] = false ; } for (i = 0 ; i < al_graph->num_vertexes; i++) { if (!visited_[i]) { DFS(al_graph, i); } } }
对比两个不同存储结构的深度优先遍历算法,对于 n 个顶点 e 条边的图来说,邻接矩阵由于是二维数组,要查找每个顶点的邻接点需要访问矩阵中的所有元素,因此都需要$O(n^2)$的时间。而邻接表做存储结构时,找邻接点所需的时间取决于顶点和边的数量,所以是$O(n+e)$显然对于点多边少的稀疏图来说,邻接表结构使得算法在时间效率上大大提高。
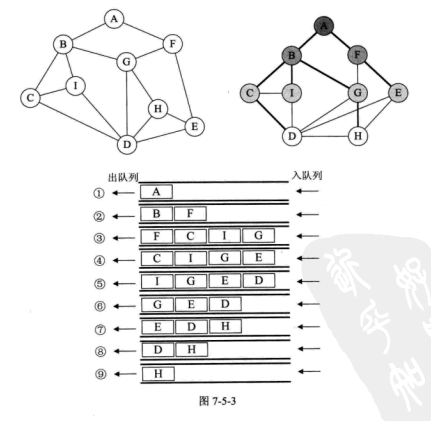
广度优先遍历 广度优先遍历 (Breadth_First_Search),又称为广度优先搜索,简称 BFS 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 void BFSTraverseAM (AMGraph<VertexType, EdgeType> *&am_graph) using namespace std ; int i, j; queue <int > vertex_queue; for (i = 0 ; i < am_graph->num_vertexes; i++) { visited[i] = false ; } for (i = 0 ; i < am_graph->num_vertexes; i++) { if (!visited[i]) { visited[i] = true ; cout << am_graph->vexs[i] << endl ; vertex_queue.push(i); while (!vertex_queue.empty()) { i = vertex_queue.front(); vertex_queue.pop(); for (j = 0 ; j < am_graph->num_vertexes; j++) { if (am_graph->arc[i][j] == 1 && !visited[j]) { visited[j] = true ; cout << am_graph->vexs[j] << endl ; vertex_queue.push(j); } } } } } } void BFSTraverseAL (ALGraph<VertexType, EdgeType> *&al_graph) using namespace std ; int i; queue <int > vertex_queue; EdgeNode<EdgeType> *edge; for (i = 0 ; i < al_graph->num_vertexes; i++) { visited_[i] = false ; } for (i = 0 ; i < al_graph->num_vertexes; i++) { if (!visited_[i]) { visited_[i] = true ; cout << al_graph->adj_list[i].data << endl ; vertex_queue.push(i); while (!vertex_queue.empty()) { i = vertex_queue.front(); vertex_queue.pop(); edge = al_graph->adj_list[i].firstedge; while (edge) { if (!visited_[edge->adjvex]) { visited_[edge->adjvex] = true ; cout << al_graph->adj_list[edge->adjvex].data << endl ; vertex_queue.push(edge->adjvex); } edge = edge->next; } } } } }
图的深度优先遍历与广度优先遍历算法在时间复杂度上是一样的,不同之处仅仅在于对顶点访问的顺序不同。深度优先更适合目标比较明确,以找到目标为主要目的的情况,而广度优先更适合在不断扩大遍历范围时找到相对最优解的情况。
最小生成树 我们把构造连通网的最小代价生成树称为最小生成树 (Minimum Cost Spanning Tree)。
普里姆 (Prim) 算法 普里姆 (Prim) 算法是以某顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 template <typename VertexType, typename EdgeType>void Graph<VertexType, EdgeType>::MiniSpanTreePrim(AMGraph<VertexType, EdgeType> *&am_graph) { using namespace std ; int min , i, j, k; vector <int > adjvex, lowcost; lowcost.push_back(0 ); adjvex.push_back(0 ); for (i = 1 ; i < am_graph->num_vertexes; i++) { lowcost.push_back(am_graph->arc[0 ][i]); adjvex.push_back(0 ); } for (i = 1 ; i < am_graph->num_vertexes; i++) { min = MY_INFINITY; j = 1 ; k = 0 ; while (j < am_graph->num_vertexes) { if (lowcost[j] != 0 && lowcost[j] < min ) { min = lowcost[j]; k = j; } ++j; } cout << "(" << adjvex[k] << "," << k << ") " ; lowcost[k] = 0 ; for (j = 1 ; j < am_graph->num_vertexes; j++) { if (lowcost[j] != 0 && am_graph->arc[k][j] < lowcost[j]) { lowcost[j] = am_graph->arc[k][j]; adjvex[j] = k; } } } }
由算法代码中的循环嵌套可得知此算法的时间复杂度为$O(n^2)$。
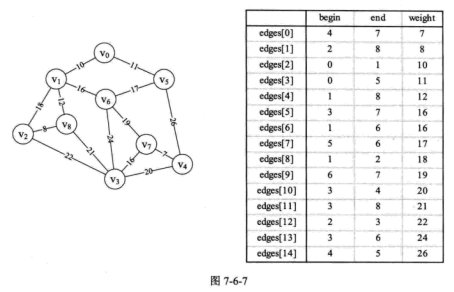
克鲁斯卡尔 (Kruskal) 算法 克鲁斯卡尔算法将各边按照权值大小排序,由小到大逐步连接顶点来构造最小生成树。1 2 3 4 5 6 template <typename EdgeType>struct KruskalEdge { int begin ; int end ; EdgeType weight; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 template <typename VertexType, typename EdgeType>void Graph<VertexType, EdgeType>::MiniSpanTreeKruskal(AMGraph<VertexType, EdgeType> *&am_graph) { using namespace std ; int i, j, n, m; vector <KruskalEdge<EdgeType>> edges; vector <int > parent(am_graph->num_vertexes, 0 ); KruskalEdge<EdgeType> kruskal_edge; for (i = 0 ; i < am_graph->num_vertexes; i++) { for (j = i+1 ; j < am_graph->num_vertexes; j++) { if (am_graph->arc[i][j] != MY_INFINITY) { kruskal_edge.begin = i; kruskal_edge.end = j; kruskal_edge.weight = am_graph->arc[i][j]; edges.push_back(kruskal_edge); } } } sort(edges.begin (), edges.end (), CompareWeight); for (i = 0 ; i < am_graph->num_edges; i++) { n = FindIndex(parent, edges[i].begin ); m = FindIndex(parent, edges[i].end ); if (n != m) { parent[n] = m; cout << "(" << edges[i].begin << "," << edges[i].end << ") " << edges[i].weight << endl ; } } } static bool CompareWeight (const KruskalEdge<EdgeType> &first, const KruskalEdge<EdgeType> &second) return first.weight < second.weight; } int FindIndex (std ::vector <int > &parent, int f) while (parent[f] > 0 ) { f = parent[f]; } return f; }
此算法的 FindIndex 函数由边数 edges 决定,时间复杂度为$O(logn)$,而外面有一个 for 循环 e 次。所以克鲁斯卡尔算法的时间复杂度为$O(nlogn)$。
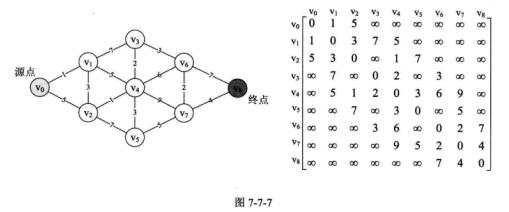
最短路径 对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第—个顶点是源点,最后一个顶点是终点。
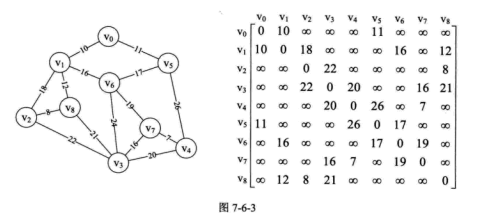
迪杰斯特拉 (Dijkstra) 算法 这是一个按路径长度递增的次序产生最短路径的算法。该算法一步步求出源点和终点之间顶点的最短路径,过程中都是基于已经求出的最短路径的基础上,求得更远顶点的最短路径,最终得到源点到终点的最短路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 std ::vector <int > path_matrix_, short_path_table_; template <typename VertexType, typename EdgeType>void Graph<VertexType, EdgeType>::ShortestPathDijkstra(AMGraph<VertexType, EdgeType> *&am_graph, int v0, std ::vector <int > &path_matrix, std ::vector <int > &short_path_table) { using namespace std ; int v, w, k, min ; vector <int > final_short_path(am_graph->num_vertexes, 0 ); for (v = 0 ; v < am_graph->num_vertexes; v++) { path_matrix.push_back(0 ); short_path_table.push_back(am_graph->arc[v0][v]); } short_path_table[v0] = 0 ; final_short_path[v0] = 1 ; for (v = 1 ; v < am_graph->num_vertexes; v++) { min = MY_INFINITY; for (w = 0 ; w < am_graph->num_vertexes; w++) { if (final_short_path[w] == 0 && short_path_table[w] < min ) { k = w; min = short_path_table[w]; } } final_short_path[k] = 1 ; for (w = 0 ; w < am_graph->num_vertexes; w++) { if (final_short_path[w] == 0 && (min + am_graph->arc[k][w] < short_path_table[w])) { path_matrix[w] = k; short_path_table[w] = min + am_graph->arc[k][w]; } } } }
迪杰斯特拉 (Dijkstra) 算法解决了从某个源点到其余各顶点的最短路径问题。从循环嵌套可以很容易得到此算法的时间复杂度为$O(n^2)$。
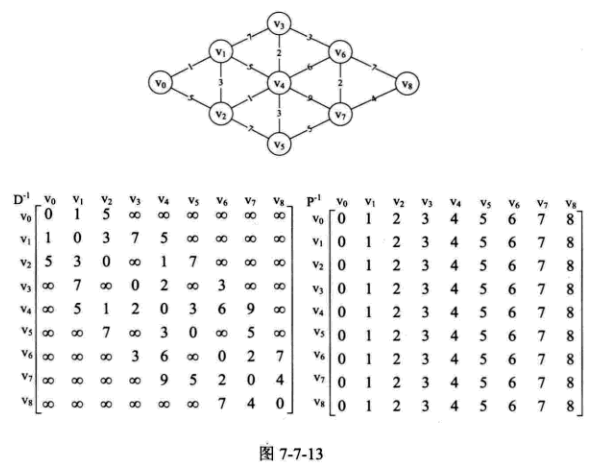
弗洛伊德 (Floyd) 算法 示例如图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 std ::vector <std ::vector <int >> floyd_path_matrix_, floyd_short_path_; template <typename VertexType, typename EdgeType>void Graph<VertexType, EdgeType>::ShortestPathFloyd(AMGraph<VertexType, EdgeType> *&am_graph, std ::vector <std ::vector <int >> &floyd_path_matrix, std ::vector <std ::vector <int >> &floyd_short_path) { using namespace std ; int v, w, k; floyd_path_matrix.resize(am_graph->num_vertexes); floyd_short_path.resize(am_graph->num_vertexes); for (v = 0 ; v < am_graph->num_vertexes; v++) { floyd_path_matrix[v].resize(am_graph->num_vertexes); floyd_short_path[v].resize(am_graph->num_vertexes); } for (v = 0 ; v < am_graph->num_vertexes; v++) { for (w = 0 ; w < am_graph->num_vertexes; w++) { floyd_short_path[v][w] = am_graph->arc[v][w]; floyd_path_matrix[v][w] = w; } } for (k = 0 ; k < am_graph->num_vertexes; k++) { for (v = 0 ; v < am_graph->num_vertexes; v++) { for (w = 0 ; w < am_graph->num_vertexes; w++) { if (floyd_short_path[v][w] > floyd_short_path[k][v] + floyd_short_path[k][w]) { floyd_short_path[v][w] = floyd_short_path[k][v] + floyd_short_path[k][w]; floyd_path_matrix[v][w] = floyd_path_matrix[v][k]; } } } } }
弗洛伊德 (Floyd) 算法,它的代码简洁到就是一个二重循环初始化加一个三重循环权值修正,就完成了所有顶点到所有顶点的最短路径计算。如此简单的实现,真是巧妙之极。很可惜由于它的三重循
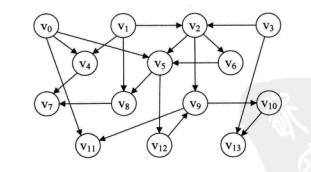
拓扑排序 在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为 AOV 网 (Activity On Vertex Network)。
1 2 3 4 5 6 template <typename VertexType, typename EdgeType>struct VertexNode { int in; VertexType data; EdgeNode<EdgeType> *firstedge; };
示例有向图如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 template <typename VertexType, typename EdgeType>bool Graph<VertexType, EdgeType>::TopologicalSort(ALGraph<VertexType, EdgeType> *&al_graph) { using namespace std ; int i, k, get_top; int count = 0 ; EdgeNode<EdgeType> *edge; stack <int > vertex_stack; for (i = 0 ; i < al_graph->num_vertexes; i++) { for (edge = al_graph->adj_list[i].firstedge; edge; edge = edge->next) { al_graph->adj_list[edge->adjvex].in++; } } for (i = 0 ; i < al_graph->num_vertexes; i++) { if (al_graph->adj_list[i].in == 0 ) { vertex_stack.push(i); } } while (!vertex_stack.empty()) { get_top = vertex_stack.top(); vertex_stack.pop(); cout << al_graph->adj_list[get_top].data << " -> " ; ++count; for (edge = al_graph->adj_list[get_top].firstedge; edge; edge = edge->next) { k = edge->adjvex; if (!(--al_graph->adj_list[k].in)) { vertex_stack.push(k); } } } if (count < al_graph->num_vertexes) { return false ; } else { return true ; } }
对一个具有 n 个顶点 edge 条弧的 AOV 网来说,扫描顶点表,将入度为 0 的顶点入栈的时间复杂为 $O(n)$,而之后的 while 循环中,每个顶点进一次栈,出一次栈,入度减 1 的操作共执行了 edge 次,所以整个算法的时间复杂度为$O(n+edge)$。